Deployment Patterns
Arc Enterprise supports two clustering topologies, each optimized for a different operational environment. The choice is about where the Parquet files live — and that decision shapes durability, cost, and the operational model of your cluster.
The Two Patterns
Pattern A: Shared Object Storage
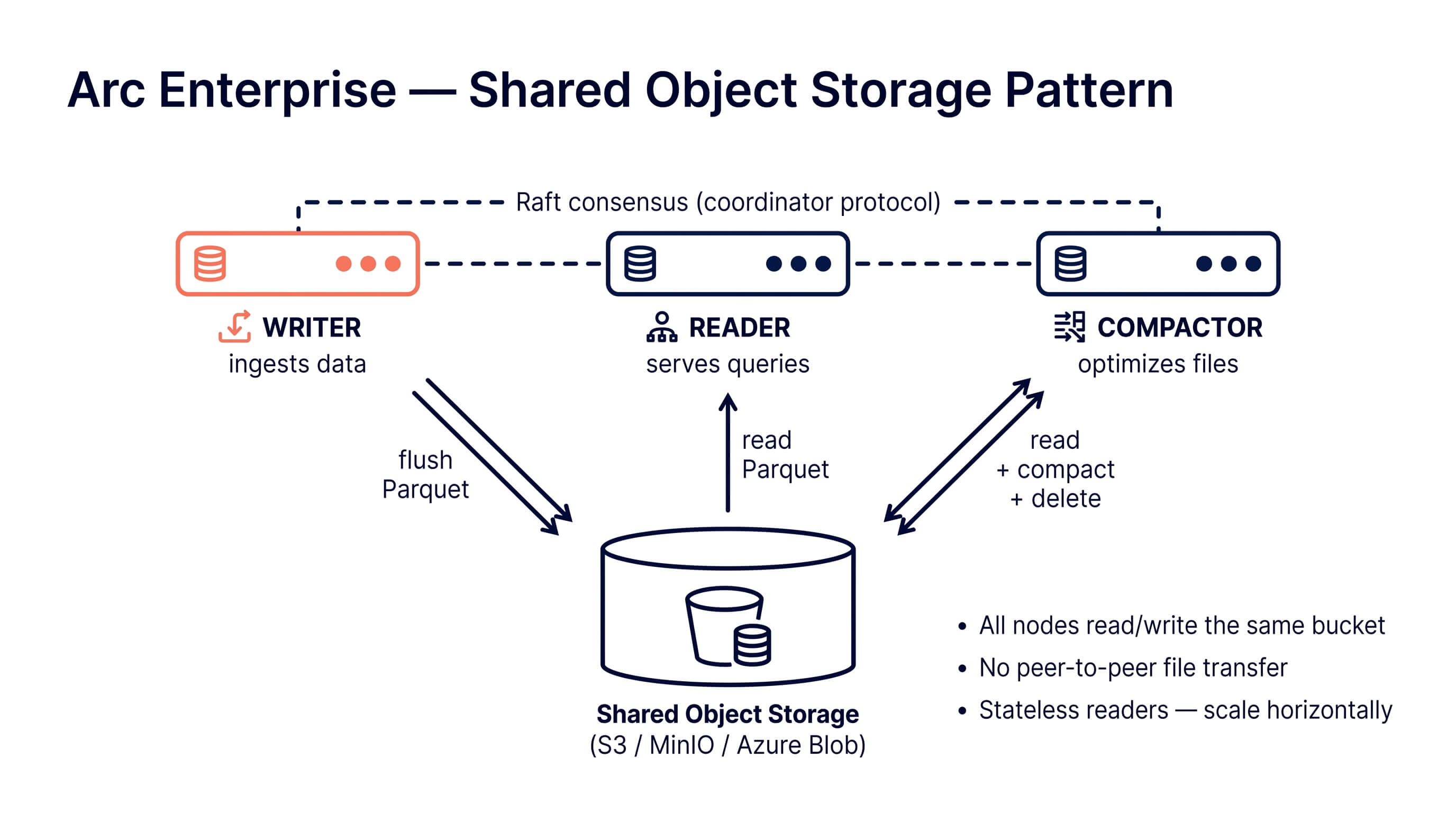
All nodes read and write to the same object store — S3, MinIO, or Azure Blob. The bucket is the source of truth for Parquet files. Nodes are stateless from a data perspective: any reader can serve any query because every file is one API call away.
Best for:
- Cloud deployments (AWS, GCP, Azure)
- Teams that already operate object storage
- Workloads where scaling readers elastically matters more than query latency
- Kubernetes-native deployments with object storage
Pattern B: Local Storage with Peer Replication
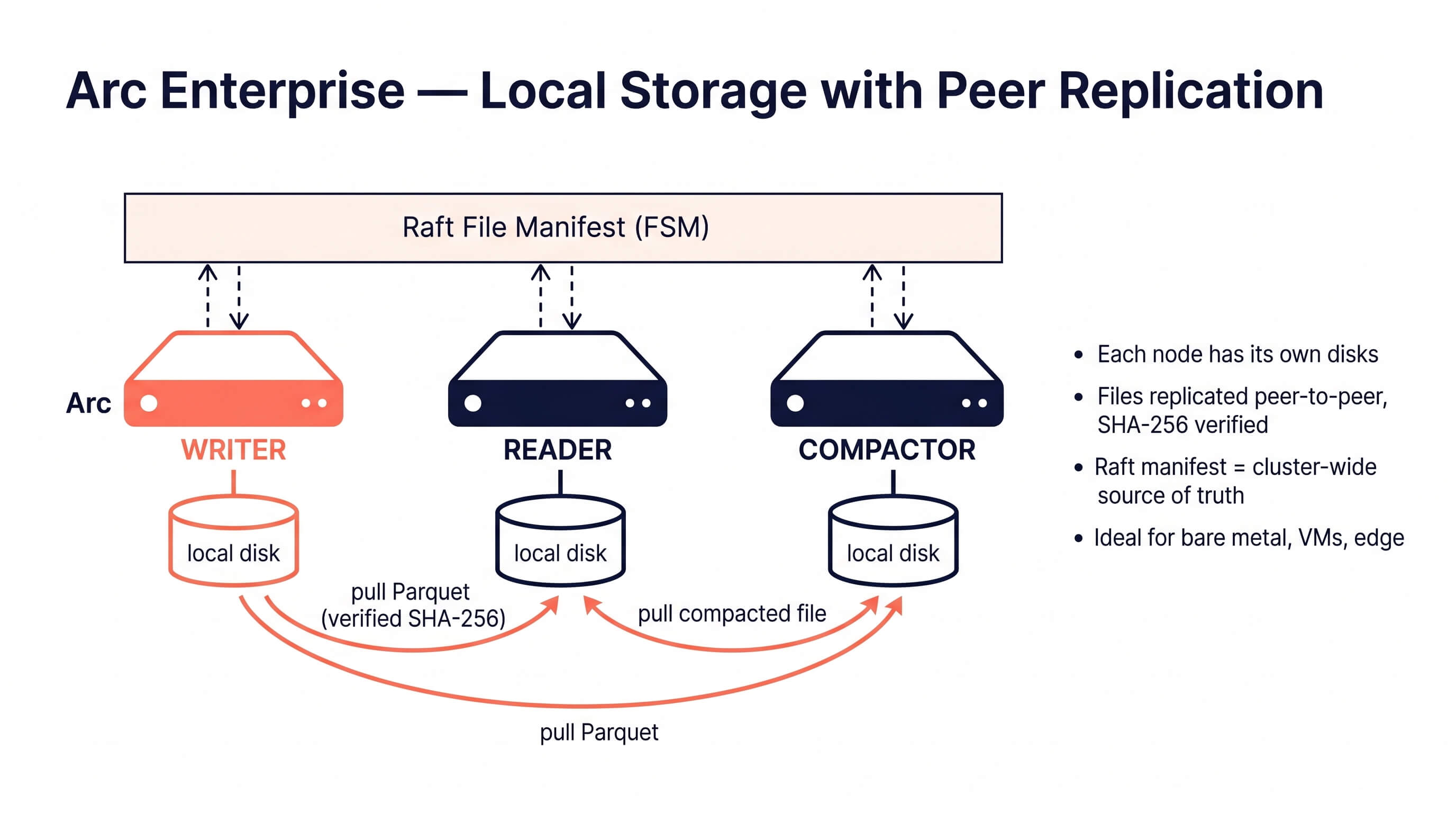
Each node has its own local disks (NVMe, SSD, or attached block storage). Parquet files are replicated peer-to-peer over the cluster protocol, verified via SHA-256, and kept on every node that needs them. A Raft-backed file manifest is the cluster-wide source of truth for which files exist.
Best for:
- Bare metal and virtual machine deployments
- Edge, on-premises, and air-gapped environments
- Defense, aerospace, industrial, and regulated workloads where shared object storage is not available
- Deployments that need the lowest possible query latency (local NVMe beats network-attached storage every time)
Side-by-Side Comparison
| Aspect | Shared Object Storage | Local Storage + Peer Replication |
|---|---|---|
| Storage layout | Single bucket, all nodes read/write | Per-node local disks, replicated peer-to-peer |
| Source of truth | The bucket itself | Raft-backed file manifest (FSM) |
| Durability | Relies on S3/MinIO/Azure replication | Replicated across N cluster nodes |
| Query latency | Network fetch from object store | Local disk I/O |
| New-node bootstrap | Instant (no data transfer needed) | Startup catch-up pulls bytes from peers |
| Compactor outputs | Written once to bucket, visible to all | Compactor writes locally, Raft announces, peers pull |
| Compactor failover | Any healthy node can take over | Any healthy node can take over |
| Best deployment | Kubernetes, cloud-native | Bare metal, VMs, edge |
| Cost model | Object storage API calls + egress | Local disk capacity × nodes |
| Network requirements | Reliable path to object store | Reliable path between cluster nodes |
Choosing a Pattern
Start here:
- Do you already run S3/MinIO/Azure in production? → Pattern A (shared).
- Do your nodes have fast local disks and you want minimum query latency? → Pattern B (local).
- Is shared object storage unavailable (edge, air-gap, defense)? → Pattern B (local).
- Do you expect to scale readers elastically based on demand? → Pattern A (shared).
- Do you need a single-digit-ms query path? → Pattern B (local).
You can also mix — a cluster can use shared object storage for cold data (tiered storage to S3 Glacier) while keeping hot data on local disks. See Tiered Storage.
Pattern A — Shared Storage Setup
Minimal 3-node cluster (1 writer, 1 reader, 1 compactor) on MinIO
# docker-compose.yml
services:
minio:
image: minio/minio
command: server /data --console-address ":9001"
environment:
MINIO_ROOT_USER: minioadmin
MINIO_ROOT_PASSWORD: minioadmin123
ports: ["9001:9001"]
arc-writer:
image: basekick/arc:latest
environment:
ARC_LICENSE_KEY: "ARC-XXXX-XXXX-XXXX-XXXX"
ARC_STORAGE_BACKEND: minio
ARC_STORAGE_S3_BUCKET: arc-data
ARC_STORAGE_S3_ENDPOINT: minio:9000
ARC_STORAGE_S3_ACCESS_KEY: minioadmin
ARC_STORAGE_S3_SECRET_KEY: minioadmin123
ARC_STORAGE_S3_USE_SSL: "false"
ARC_STORAGE_S3_PATH_STYLE: "true"
ARC_CLUSTER_ENABLED: "true"
ARC_CLUSTER_NODE_ID: writer-01
ARC_CLUSTER_ROLE: writer
ARC_CLUSTER_CLUSTER_NAME: production
ARC_CLUSTER_RAFT_BOOTSTRAP: "true"
ARC_CLUSTER_SHARED_SECRET: "your-cluster-secret"
ARC_CLUSTER_REPLICATION_ENABLED: "false" # not needed on shared storage
ports: ["8001:8000"]
arc-reader:
image: basekick/arc:latest
environment:
ARC_LICENSE_KEY: "ARC-XXXX-XXXX-XXXX-XXXX"
ARC_STORAGE_BACKEND: minio
ARC_STORAGE_S3_BUCKET: arc-data
ARC_STORAGE_S3_ENDPOINT: minio:9000
ARC_STORAGE_S3_ACCESS_KEY: minioadmin
ARC_STORAGE_S3_SECRET_KEY: minioadmin123
ARC_STORAGE_S3_USE_SSL: "false"
ARC_STORAGE_S3_PATH_STYLE: "true"
ARC_CLUSTER_ENABLED: "true"
ARC_CLUSTER_NODE_ID: reader-01
ARC_CLUSTER_ROLE: reader
ARC_CLUSTER_CLUSTER_NAME: production
ARC_CLUSTER_SEEDS: arc-writer:9200
ARC_CLUSTER_SHARED_SECRET: "your-cluster-secret"
ports: ["8002:8000"]
arc-compactor:
image: basekick/arc:latest
environment:
ARC_LICENSE_KEY: "ARC-XXXX-XXXX-XXXX-XXXX"
ARC_STORAGE_BACKEND: minio
ARC_STORAGE_S3_BUCKET: arc-data
ARC_STORAGE_S3_ENDPOINT: minio:9000
ARC_STORAGE_S3_ACCESS_KEY: minioadmin
ARC_STORAGE_S3_SECRET_KEY: minioadmin123
ARC_STORAGE_S3_USE_SSL: "false"
ARC_STORAGE_S3_PATH_STYLE: "true"
ARC_CLUSTER_ENABLED: "true"
ARC_CLUSTER_NODE_ID: compactor-01
ARC_CLUSTER_ROLE: compactor
ARC_CLUSTER_CLUSTER_NAME: production
ARC_CLUSTER_SEEDS: arc-writer:9200
ARC_CLUSTER_SHARED_SECRET: "your-cluster-secret"
ARC_CLUSTER_FAILOVER_ENABLED: "true"
ARC_COMPACTION_ENABLED: "true"
ports: ["8003:8000"]
Key points
- All nodes point to the same bucket. The writer flushes to the bucket; readers query directly from it; the compactor reads source files, writes compacted outputs back, and deletes the sources.
ARC_CLUSTER_REPLICATION_ENABLED=falseis the right choice on shared storage — there's no peer-to-peer file transfer needed because the bucket is already shared.- Exactly one compactor node. Multiple compactors against a shared bucket produce duplicate outputs. Arc warns you via the cluster health check if it sees more than one.
- Compactor failover (
ARC_CLUSTER_FAILOVER_ENABLED=true) lets the Raft leader automatically reassign the compactor lease to another healthy node if the current compactor dies. No restart required.
Pattern B — Local Storage Setup
Minimal 3-node cluster (1 writer, 1 reader, 1 compactor) on local disks
# docker-compose.yml
services:
arc-writer:
image: basekick/arc:latest
environment:
ARC_LICENSE_KEY: "ARC-XXXX-XXXX-XXXX-XXXX"
ARC_STORAGE_BACKEND: local
ARC_STORAGE_LOCAL_PATH: /app/data
ARC_CLUSTER_ENABLED: "true"
ARC_CLUSTER_NODE_ID: writer-01
ARC_CLUSTER_ROLE: writer
ARC_CLUSTER_CLUSTER_NAME: production
ARC_CLUSTER_RAFT_BOOTSTRAP: "true"
ARC_CLUSTER_SHARED_SECRET: "your-cluster-secret"
ARC_CLUSTER_REPLICATION_ENABLED: "true" # CRITICAL for local storage
volumes:
- writer-data:/app/data
ports: ["8001:8000"]
arc-reader:
image: basekick/arc:latest
environment:
ARC_LICENSE_KEY: "ARC-XXXX-XXXX-XXXX-XXXX"
ARC_STORAGE_BACKEND: local
ARC_STORAGE_LOCAL_PATH: /app/data
ARC_CLUSTER_ENABLED: "true"
ARC_CLUSTER_NODE_ID: reader-01
ARC_CLUSTER_ROLE: reader
ARC_CLUSTER_CLUSTER_NAME: production
ARC_CLUSTER_SEEDS: arc-writer:9200
ARC_CLUSTER_SHARED_SECRET: "your-cluster-secret"
ARC_CLUSTER_REPLICATION_ENABLED: "true"
volumes:
- reader-data:/app/data
ports: ["8002:8000"]
arc-compactor:
image: basekick/arc:latest
environment:
ARC_LICENSE_KEY: "ARC-XXXX-XXXX-XXXX-XXXX"
ARC_STORAGE_BACKEND: local
ARC_STORAGE_LOCAL_PATH: /app/data
ARC_CLUSTER_ENABLED: "true"
ARC_CLUSTER_NODE_ID: compactor-01
ARC_CLUSTER_ROLE: compactor
ARC_CLUSTER_CLUSTER_NAME: production
ARC_CLUSTER_SEEDS: arc-writer:9200
ARC_CLUSTER_SHARED_SECRET: "your-cluster-secret"
ARC_CLUSTER_REPLICATION_ENABLED: "true"
ARC_CLUSTER_FAILOVER_ENABLED: "true"
ARC_COMPACTION_ENABLED: "true"
volumes:
- compactor-data:/app/data
ports: ["8003:8000"]
volumes:
writer-data:
reader-data:
compactor-data:
How peer replication works
- Writer flushes a Parquet file locally. The file hash (SHA-256) is computed and included in the flush.
- The writer registers the file in the Raft manifest via a
CommandRegisterFileentry. This commits cluster-wide — every node now knows the file exists and where to find it. - Readers and compactors observe the FSM callback. A background puller enqueues a byte-level pull from the origin peer (or any healthy peer that has a copy).
- The puller fetches over the cluster protocol, streams bytes, verifies the SHA-256 against the manifest, and writes to local storage. Checksum mismatches trigger retries; failed pulls fall back to other peers.
- On node restart, a startup catch-up walker reconciles the local manifest against the Raft FSM and pulls any files the node missed.
Key points
ARC_CLUSTER_REPLICATION_ENABLED=trueis required — this enables the file manifest and peer puller.- Each node has its own volume. No shared volume, no NFS, no clustered filesystem — the replication is the primary data-plane mechanism.
- Shared secret is mandatory. Peer fetch requests are HMAC-authenticated with the shared secret; Arc refuses to start replication without one.
- Raft leader is the writer by default.
ARC_CLUSTER_RAFT_BOOTSTRAP=trueon the writer makes it bootstrap Raft; other nodes join via the seed. Non-leader nodes forward manifest commands to the leader transparently.
Compacted file distribution
Compaction on local storage works the same way as ingest:
- The compactor reads source Parquet files (from local storage, pulling from peers if missing).
- It produces a compacted output, writes it to its own local disk.
- It registers the new file in the Raft manifest and marks the source files as deleted.
- Every other node sees the manifest change: readers pull the compacted bytes from the compactor, and delete their local copies of the source files.
Security Notes
Both patterns share the same security posture:
- Shared secret authentication (
cluster.shared_secret) — required for peer discovery and, in Pattern B, for all peer file fetches. Arc refuses to boot if replication is enabled without a shared secret. - TLS encryption (
cluster.tls_enabled) — optional but recommended. Encrypts the inter-node coordinator protocol, Raft transport, and peer file transfers. - Role-based authorization on manifest mutations — only nodes with
CanIngest(writers) orCanCompact(compactors) can forwardRegisterFile/DeleteFilecommands to the leader. Reader nodes are rejected.
See Cluster Security for full details.
Common Mistakes
- Multiple compactor nodes on shared storage. This produces duplicate compacted outputs and double-counted query results. Use exactly one
ARC_CLUSTER_ROLE=compactorand enableARC_CLUSTER_FAILOVER_ENABLED=truefor automatic failover. - Mixing shared and local storage in the same cluster. All nodes must agree on the storage model. Pick one per cluster.
- Forgetting
ARC_CLUSTER_REPLICATION_ENABLED=trueon local storage. Without it, readers will query empty local directories. - Using a shared volume (NFS, EFS) as "local" storage. Don't — the concurrent-write semantics of a shared POSIX filesystem aren't what Arc expects, and you lose the durability guarantees of either pattern. Either go full shared object storage or full per-node local disks.
Next Steps
- Clustering Configuration Reference — full list of cluster config options
- Tiered Storage — combine local hot storage with cold object storage
- Cluster Security — TLS and shared secret configuration