Clustering & High Availability
Scale Arc horizontally with multi-node clusters. Separate write, read, and compaction workloads across dedicated nodes with automatic failover.
Arc Enterprise supports two cluster topologies: shared object storage and local storage with peer replication. See Deployment Patterns to choose the right one for your environment before configuring a cluster.
Overview
Arc Enterprise clustering uses a role-based architecture where each node in the cluster serves a specific purpose:
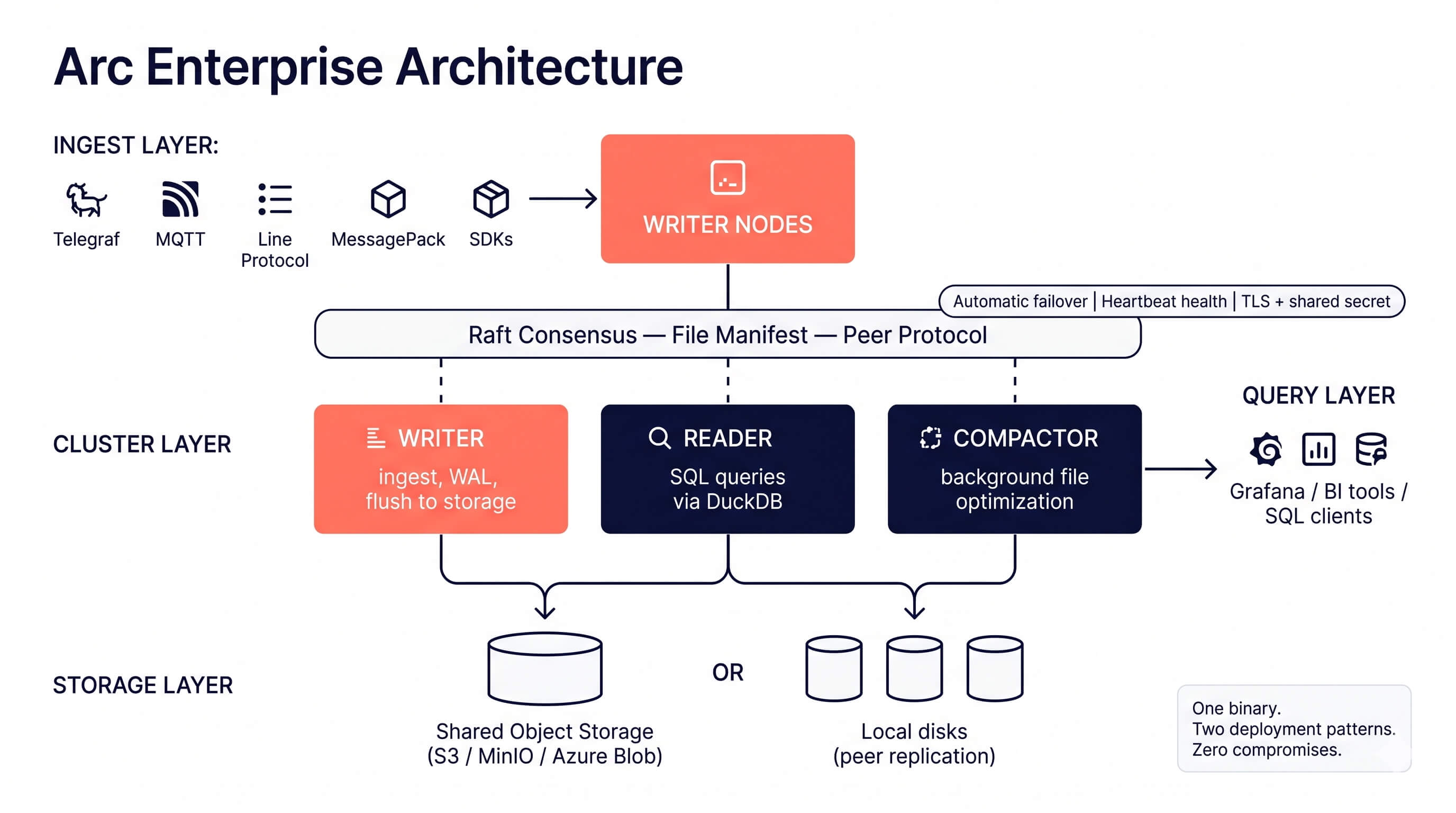
Node Roles
| Role | Purpose | Capabilities |
|---|---|---|
| writer | Handles data ingestion and WAL | Ingest, coordinate |
| reader | Serves queries from shared storage | Query |
| compactor | Runs background file optimization | Compact |
| standalone | Single-node mode (default) | All capabilities |
- Writers receive data via the ingestion API, buffer it, and flush Parquet files to shared storage. WAL replication ensures durability.
- Readers query data directly from shared storage using DuckDB. Scale readers horizontally to handle more concurrent queries.
- Compactors run hourly and daily file compaction in the background without impacting write or read performance.
Configuration
TOML Configuration
[cluster]
enabled = true
node_id = "writer-01" # Unique identifier for this node
role = "writer" # writer, reader, compactor, standalone
cluster_name = "production" # Cluster identifier
seeds = ["10.0.1.10:9000", "10.0.1.11:9000"] # Seed nodes for discovery
coordinator_addr = ":9000" # Address for inter-node communication
health_check_interval = 10 # Health check interval (seconds)
heartbeat_interval = 5 # Heartbeat interval (seconds)
replication_enabled = true # Enable WAL replication to readers
query_gate_on_catchup = false # See "Query Gating During Replication Catch-Up" below
Environment Variables
ARC_CLUSTER_ENABLED=true
ARC_CLUSTER_NODE_ID=writer-01
ARC_CLUSTER_ROLE=writer
ARC_CLUSTER_CLUSTER_NAME=production
ARC_CLUSTER_SEEDS=10.0.1.10:9000,10.0.1.11:9000
ARC_CLUSTER_COORDINATOR_ADDR=:9000
ARC_CLUSTER_HEALTH_CHECK_INTERVAL=10
ARC_CLUSTER_HEARTBEAT_INTERVAL=5
ARC_CLUSTER_REPLICATION_ENABLED=true
ARC_CLUSTER_QUERY_GATE_ON_CATCHUP=false
Query Gating During Replication Catch-Up
In a local-storage cluster with peer replication, a reader node may serve queries before its background puller has finished pulling all the Parquet files the cluster manifest references. Without gating, those queries silently return partial results: the manifest knows about the missing files, but read_parquet() globs against local storage and only finds what's already on disk. WAL replication (added in 26.05.1) closes part of this gap for unflushed writer data, but flushed Parquet files still depend on the asynchronous puller.
cluster.query_gate_on_catchup (added in 26.06.1, off by default) closes the remaining gap. When enabled, all user-facing read endpoints return 503 Service Unavailable until peer file replication has fully converged on this node.
Turn this on if you'd rather a reader return 503 for a few seconds at startup than serve incomplete results. Leave it off if your application can tolerate eventual consistency during catch-up and you'd rather queries always succeed (the existing pre-26.06.1 behavior). Either choice is defensible; this is a correctness-vs-availability knob.
What "fully converged" means
The gate is scoped to the startup catch-up batch only — not to all pull activity on the node. This distinction matters: in a busy cluster, steady-state ingest constantly puts new files in flight, and a naive "wait for everything to settle" predicate would mean the reader returns 503 every few seconds in normal operation. The gate's job is "the reader has finished bootstrapping its view of the manifest as of startup," not "no pulls are happening anywhere right now."
A node is considered ready when all of the following are true:
- The startup catch-up walker has finished its pass over the manifest.
- No paths the walker tagged are still in flight (
catchup_inflight == 0). Steady-state pulls from reactive FSM callbacks are deliberately excluded. - No catch-up-batch pulls failed after retries (
catchup_failed == 0). - No catch-up-batch pulls were dropped due to queue saturation (
catchup_dropped == 0).
Failures and drops outside the catch-up window do not keep the gate red. They're operational concerns surfaced via puller stats but not correctness blockers — by the time the catch-up batch has settled, the reader has reconciled its view of the manifest as of walker start. Steady-state failures are handled by reactive FSM callbacks (which re-enqueue), the Phase 5 reconciler, and operator alerting via the cumulative failed / dropped counters.
Self-heal: catch-up failures and drops both clear without a process restart. When a later pull succeeds for a previously-affected path (a reactive FSM callback re-enqueueing after the underlying issue resolves, or a subsequent catch-up scan), the corresponding scoped counter decrements and the gate re-opens automatically. The puller tracks affected paths in dedicated sets so it can attribute a successful pull back to the original failure or drop.
Both catchup_failed and catchup_dropped are surfaced in the 503 body so operators see exactly what happened. The /api/v1/cluster/status endpoint also exposes the cumulative failed / dropped / pulled / skipped_dup keys with their original whole-puller-lifetime semantics (preserved for dashboards landed before #392), alongside the new catchup_* keys for gate-relevant numbers. So dashboards can distinguish "the catch-up batch had a hiccup" (catchup_failed > 0) from "the puller has been having steady-state problems for hours" (failed >> catchup_failed).
replication_catchup_enabled=falseIf you set cluster.replication_catchup_enabled=false (the emergency off-switch for pathologically large manifests), the catch-up walker never runs and the gate would never clear. Arc detects this combination at startup, logs a WARN, and auto-disables the gate so the node isn't permanently 503'd. Operators see a clear log line and can fix the configuration at their leisure. Don't enable the gate if you've also disabled the walker.
Endpoints affected
When the gate is enabled and the node is still catching up, these endpoints return 503:
POST /api/v1/queryPOST /api/v1/query/arrowPOST /api/v1/query/estimateGET /api/v1/query/:measurementGET /api/v1/measurements
Internal endpoints (cache invalidation, cluster status, replication-control APIs) are deliberately not gated — peer nodes need them to fire during catch-up.
503 response shape
{
"success": false,
"error": "replication_catch_up_in_progress",
"message": "Reader is still catching up on replicated files. Retry shortly or check /api/v1/cluster for catch-up progress.",
"catchup_status": {
"started_at": 1714912800,
"completed_at": 0,
"entries_walked": 1287,
"enqueued": 1287,
"catchup_inflight": 2,
"catchup_failed": 0,
"catchup_dropped": 0,
"queue_depth": 7,
"inflight_count": 2,
"pulled": 1278
}
}
A Retry-After: 5 header is also set so HTTP-aware load balancers and clients can back off automatically.
completed_at = 0 means the catch-up walker is still enumerating; once it flips non-zero, watch queue_depth + inflight_count go to zero. Non-zero failed or dropped means the gate will not clear without a node restart or a follow-up FSM callback.
Observability
- Cumulative gate fires:
QueryHandler.QueryGate503Total()is exposed for Prometheus / metrics scrapes. Alert on a non-zero rate to detect that the gate is firing without inferring from generic HTTP error logs. - Sampled log line: while the gate is active, Arc emits at most one
WARNlog per second with the gate counter and request path. Avoids flooding under sustained catch-up while still surfacing the degraded state. - Live status: the
/api/v1/clusterendpoint exposesreplication_catchup_statuswith the same fields shown in the 503 body, so dashboards can show catch-up progress without waiting for a query to fail.
Known limitation
There is a sub-millisecond window between the Raft FSM committing a RegisterFile entry and the puller's Enqueue callback firing. A query landing in that window can observe ReplicationReady() == true while a manifest entry from the same Raft commit is not yet in the in-flight set. Closing this gap requires a per-query Raft LastApplied() barrier on the query path, which is out of scope for this gate.
The gate's contract is "every file the puller has observed has been pulled," not "every file the manifest currently contains has been pulled." In practice this means the gate may unblock a fraction of a second before the very last files committed before the gate-clear are queryable. This is a tracked follow-up.
Pattern A vs. Pattern B
- Shared object storage (Pattern A): the puller is disabled (
replication_enabled = false), soquery_gate_on_catchupis effectively a no-op — readers see the bucket directly and don't need to catch up. Safe to leave the flag at any value. - Local storage with peer replication (Pattern B): this is where the gate matters. Enable it on readers whose application cannot tolerate partial results during cold start or after a network partition.
Deployment Example
A minimal 3-node cluster with one writer and two readers using Docker Compose:
# docker-compose.yml
version: "3.8"
services:
# Shared storage (MinIO as S3-compatible backend)
minio:
image: minio/minio
command: server /data --console-address ":9001"
environment:
MINIO_ROOT_USER: minioadmin
MINIO_ROOT_PASSWORD: minioadmin123
ports:
- "9001:9001"
# Writer node (primary)
arc-writer:
image: basekick/arc:latest
environment:
ARC_LICENSE_KEY: "ARC-XXXX-XXXX-XXXX-XXXX"
ARC_STORAGE_BACKEND: minio
ARC_STORAGE_S3_BUCKET: arc-data
ARC_STORAGE_S3_ENDPOINT: minio:9000
ARC_STORAGE_S3_ACCESS_KEY: minioadmin
ARC_STORAGE_S3_SECRET_KEY: minioadmin123
ARC_STORAGE_S3_USE_SSL: "false"
ARC_STORAGE_S3_PATH_STYLE: "true"
ARC_CLUSTER_ENABLED: "true"
ARC_CLUSTER_NODE_ID: writer-01
ARC_CLUSTER_ROLE: writer
ARC_CLUSTER_CLUSTER_NAME: production
ARC_CLUSTER_COORDINATOR_ADDR: ":9000"
ARC_CLUSTER_REPLICATION_ENABLED: "true"
ARC_AUTH_ENABLED: "true"
ports:
- "8000:8000"
# Reader node 1
arc-reader-1:
image: basekick/arc:latest
environment:
ARC_LICENSE_KEY: "ARC-XXXX-XXXX-XXXX-XXXX"
ARC_STORAGE_BACKEND: minio
ARC_STORAGE_S3_BUCKET: arc-data
ARC_STORAGE_S3_ENDPOINT: minio:9000
ARC_STORAGE_S3_ACCESS_KEY: minioadmin
ARC_STORAGE_S3_SECRET_KEY: minioadmin123
ARC_STORAGE_S3_USE_SSL: "false"
ARC_STORAGE_S3_PATH_STYLE: "true"
ARC_CLUSTER_ENABLED: "true"
ARC_CLUSTER_NODE_ID: reader-01
ARC_CLUSTER_ROLE: reader
ARC_CLUSTER_CLUSTER_NAME: production
ARC_CLUSTER_SEEDS: arc-writer:9000
ARC_AUTH_ENABLED: "true"
ports:
- "8001:8000"
# Reader node 2
arc-reader-2:
image: basekick/arc:latest
environment:
ARC_LICENSE_KEY: "ARC-XXXX-XXXX-XXXX-XXXX"
ARC_STORAGE_BACKEND: minio
ARC_STORAGE_S3_BUCKET: arc-data
ARC_STORAGE_S3_ENDPOINT: minio:9000
ARC_STORAGE_S3_ACCESS_KEY: minioadmin
ARC_STORAGE_S3_SECRET_KEY: minioadmin123
ARC_STORAGE_S3_USE_SSL: "false"
ARC_STORAGE_S3_PATH_STYLE: "true"
ARC_CLUSTER_ENABLED: "true"
ARC_CLUSTER_NODE_ID: reader-02
ARC_CLUSTER_ROLE: reader
ARC_CLUSTER_CLUSTER_NAME: production
ARC_CLUSTER_SEEDS: arc-writer:9000
ARC_AUTH_ENABLED: "true"
ports:
- "8002:8000"
High Availability
Arc Enterprise's HA model depends on which deployment pattern you chose. Both deliver "writer crash recovered without operator intervention," but the mechanics are very different.
Pattern 2 — Shared object storage (multi-writer)
When all nodes share an object-storage backend (S3, Azure Blob, MinIO), Arc Enterprise runs in multi-writer mode: N writer nodes accept writes concurrently behind a load balancer. There is no "primary writer" to fail over to — every writer is a peer, and the load balancer handles writer-crash recovery via its own health-check.
Key characteristics:
- Recovery time: immediate — the next request lands on a surviving writer via the LB
- Health-based detection: load balancer polls each writer's
/readyendpoint (Kubernetes Service, Traefik, nginx, HAProxy all support this out of the box) - No "promotion" step: all writers are equivalent for ingestion; nothing in the cluster has to elect a new "primary"
- Singleton background tasks (retention, continuous queries, deletes) run on whichever node holds the cluster Raft leadership at the time. Raft re-election on leader death is sub-second and the new leader's next scheduler tick picks up the work.
Enable by setting cluster.shared_storage_mode = true (env: ARC_CLUSTER_SHARED_STORAGE_MODE). The Helm chart sets this automatically when storage.mode=shared. Requires an Enterprise license that includes the shared_storage_multi_writer feature.
Deploy 3 writers for full HA: 1 failure is tolerated on both the ingestion side (LB routes around it) and the cluster-Raft side (quorum-of-2 still elects a leader for singleton tasks). 2 writers is not recommended — ingestion stays HA via the LB but Raft cannot elect on a single failure, so singleton tasks pause until quorum is restored. 1 writer is fine for development but has no HA.
When a writer crashes:
- The writer's
/readyendpoint stops responding (or returns 503). - The load balancer marks the writer unhealthy and stops routing to it within one poll cycle (~5–10 s).
- New writes route to the surviving writer(s). No in-cluster failover action required.
- In-flight buffer on the crashed writer (records that arrived in memory but had not yet been flushed to S3) is lost. Records that completed the S3 PUT before the crash are durable.
- On writer restart, the local WAL replays any un-flushed entries into the new Arrow buffer before
/readyflips back to 200 and the load balancer resumes routing.
Pattern 1 — Local storage with peer replication
When each node has its own local storage, Arc Enterprise runs in single-writer + multi-reader mode: one writer takes all ingest, the readers replicate the WAL in real time, and on writer failure one of the readers is promoted via Arc's in-cluster failover controller. (Pattern 1 multi-writer — per-shard writer ownership — is a future initiative; the current shipping version uses single-writer + standby readers as the HA model.)
Key characteristics:
- Recovery time: less than 30 seconds
- Health-based detection: continuous health monitoring with configurable thresholds
- Automatic promotion: a reader (acting as standby) is promoted to writer via Raft consensus (
CommandPromoteWriterFSM apply) - Cooldown protection: prevents rapid failover flapping
Enable by setting cluster.failover.enabled = true (env: ARC_CLUSTER_FAILOVER_ENABLED). Requires the writer_failover license feature.
Deploy 1 writer + 2+ readers with cluster.replication_enabled=true on the readers. The readers are the failover pool — each receives a real-time copy of the writer's WAL and can be promoted on writer failure.
When the writer fails:
- Health checks detect the failure.
- The Raft leader selects the most caught-up reader (by replication LSN).
- The selected reader is promoted to writer via
CommandPromoteWriterRaft apply. - Write traffic re-routes to the new writer (clients reconnect or the LB picks up the new writer's
/ready=200).
- Cloud-native deployments (EKS/GKE/AKS, anywhere managed S3 is available) → Pattern 2 multi-writer. Simpler operationally, scales writes horizontally, the LB does failover.
- Bare metal, on-prem, edge without easy access to S3-compatible storage → Pattern 1 with writer failover. Single-writer ceiling on throughput; HA via promotion.
See Deployment Patterns for the full trade-off comparison.
API Reference
All cluster endpoints require admin authentication.
Get Cluster Status
curl -H "Authorization: Bearer $TOKEN" \
http://localhost:8000/api/v1/cluster
Response:
{
"success": true,
"data": {
"cluster_name": "production",
"node_count": 3,
"healthy_nodes": 3,
"roles": {
"writer": 1,
"reader": 2,
"compactor": 0
}
}
}
List Cluster Nodes
# All nodes
curl -H "Authorization: Bearer $TOKEN" \
http://localhost:8000/api/v1/cluster/nodes
# Filter by role
curl -H "Authorization: Bearer $TOKEN" \
"http://localhost:8000/api/v1/cluster/nodes?role=reader"
# Filter by state
curl -H "Authorization: Bearer $TOKEN" \
"http://localhost:8000/api/v1/cluster/nodes?state=healthy"
Response:
{
"success": true,
"data": [
{
"id": "writer-01",
"role": "writer",
"state": "healthy",
"address": "10.0.1.10:9000",
"last_heartbeat": "2026-02-13T10:30:00Z"
},
{
"id": "reader-01",
"role": "reader",
"state": "healthy",
"address": "10.0.1.11:9000",
"last_heartbeat": "2026-02-13T10:30:01Z"
}
]
}
Get Specific Node
curl -H "Authorization: Bearer $TOKEN" \
http://localhost:8000/api/v1/cluster/nodes/writer-01
Get Local Node Info
curl -H "Authorization: Bearer $TOKEN" \
http://localhost:8000/api/v1/cluster/local
Cluster Health Check
curl -H "Authorization: Bearer $TOKEN" \
http://localhost:8000/api/v1/cluster/health
Response:
{
"success": true,
"data": {
"status": "healthy",
"node_id": "writer-01",
"role": "writer",
"cluster_name": "production"
}
}
Best Practices
-
Pick a deployment pattern — Use shared object storage (S3, MinIO, Azure) for cloud-native deployments, or local storage with peer replication for bare metal, VMs, and edge. Don't mix the two in the same cluster.
-
Size for HA based on pattern:
- Pattern 2 (shared storage): 3 writers behind a load balancer — tolerates 1 failure on both the ingestion path (LB routes around it) and the Raft singleton-task path (quorum still elects a leader). Single writer is fine for dev; 2 writers is not recommended (Raft quorum gap).
- Pattern 1 (local storage): 1 writer + 2 readers with
cluster.replication_enabled=trueon the readers. The readers are the failover pool — one is promoted to writer if the primary fails. Don't run 2+ writers in Pattern 1; the current single-writer model is the supported topology.
-
Scale readers independently — Add reader nodes to handle increased query load without affecting write performance.
-
Use one dedicated compactor — Run compaction on a single dedicated node to avoid duplicate outputs. Enable
ARC_CLUSTER_FAILOVER_ENABLED=truefor automatic compactor failover. -
Configure seed nodes — Reader and compactor nodes should list writer nodes as seeds for cluster discovery.
-
Always set a shared secret —
ARC_CLUSTER_SHARED_SECRETis required for peer authentication. Arc refuses to start replication without it. -
Monitor cluster health — Use the
/api/v1/cluster/healthendpoint with your monitoring system (Prometheus, Grafana) to detect issues early.
Next Steps
- RBAC — Secure your cluster with role-based access control
- Tiered Storage — Optimize storage costs with hot/cold tiering
- Audit Logging — Track all operations for compliance